

I. 서론
IPython 발전 과정 중에서 가장 큰 변화를 언급하면 단일 process로 처리하던 Read-Evaluate-Print Loop (REPL)를 Evaluate를 담당하는 kernel과 그 외 나머지 부분으로 분리한 작업이다.
decoupled two-process model 이라는 이러한 전략은 단일 kernel에 여러 클라이언트가 접속해서 작업하거나 다양한 유형의 클라이언트 개발을 지원하기 위해 도입했지만, 뜻하지 않게 단일 클라이언트에서 사용할 수 있는 다양한 커널들의 제작을 촉발했다.
게다가 기대했던 multi client 접근 문제는 web 기반의 jupyter notebook이 대세가 되면서 client application들이 kernel에 직접 연결하고 공유하는 기존 방식(console이나 qtconsole이 접근했던 방식)보다 더 간단하게 요구사항을 충족(jupyter notebook이 web server 위에서 동작하기 때문이다.)하고 있다.
그런데 web application으로 구현한 front-end가 출현하여 여러가지 편의성과 이점을 제공했다면, 또 다른 부분인 jupyter notebook과 kernel 사이에서는 변화가 있었을까?
이 문서에서는 jupyter notebook과 kernel 간 연결 방식을 조사하고 더 나아가 각 연결 방식이 주는 효과에 대해서 이야기하고자한다.
II. 관련 기술/연구, 선행작업
Jupyter Notebook의 Web Interface Menu를 사용해서 kernel 연결
먼저, 일반적으로 사용자가 notebook에서 kernel을 사용하는 방식에 대해서 살펴본다.
jupyter notebook web ui에서 kernel을 실행하는 일련의 과정을 다음 다이어그램에 요약했다.
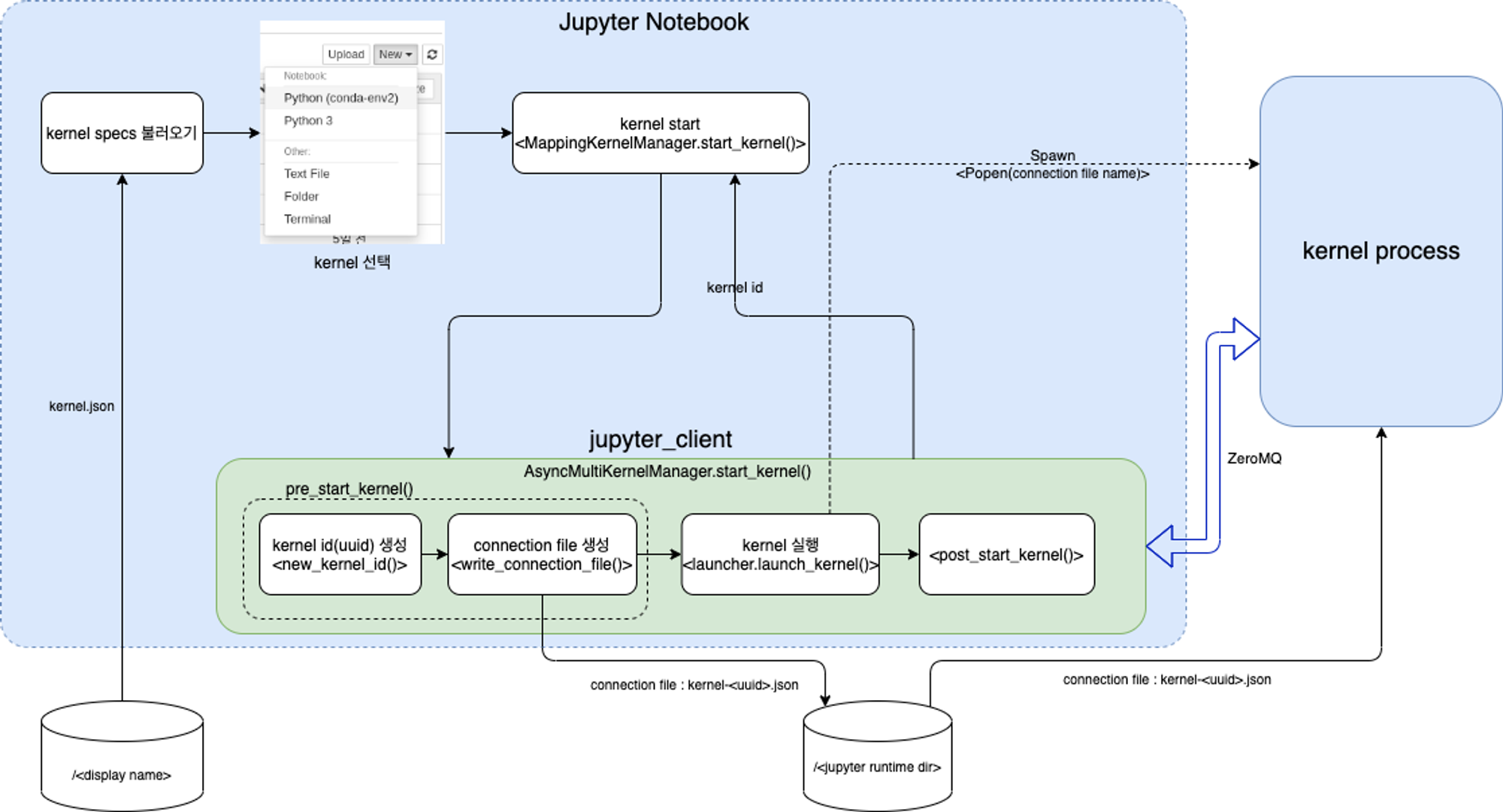
jupyter notebook에서 현재 사용할 수 있는 커널을 확인하려면, kernel 설치 과정에서 그 kernel에 대한 정보를 확인할 수 있도록 kernelspec 등록 과정을 추가로 진행해야한다.
kernelspec을 등록할 때 입력한 "display name" 항목은 jupyter notebook의 kernel 목록에 표시할 kernel 이름이자 kernel spec 관련 파일을 저장할 디렉토리 이름이다.
이 디렉토리에 kernel.json, kernel.js, 기타 그림 파일을 저장하는데 이 중 kernel.json 파일 내부에 설치한 kernel 정보가 들어있다.

<jupyter kernelspec 확인>
jupyter notebook는 이 파일을 참고해서 사용할 수 있는 kernel 목록을 보여주고 사용자가 선택하면 그것을 실행한다.
jupyter notebook 내부로 더 들어가서 살펴보면, kernel 관련 작업들 대부분은 jupyter_client라는 모듈에서 처리한다.
jupyter_client는 Jupyter kernel을 시작, 관리하고 통신하기 위한 Python API를 제공하는 모듈로 kernel process를 새로 생성하는 과정에 관여한다.
jupyter_client는 먼저 jupyter_runtime_dir 디렉토리 아래에 kernel 통신을 위한 정보를 담고 있는 connection file을 만들고, subprocess를 만들면서 이 connection file의 경로를 넘긴다.
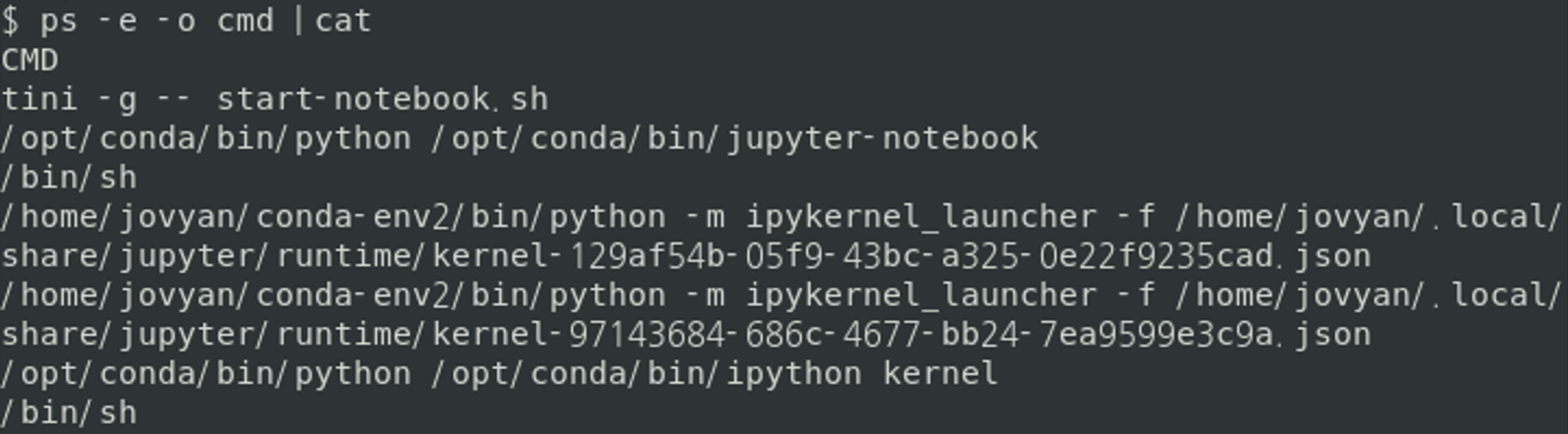
<ps 명령으로 Jupyter Notebook과 subprocess 조회한 결과>
kernel process는 인자로 넘겨받은 파일 경로에서 connection file을 읽어들여 통신에 필요한 여러 port들(5개)을 초기화하고 연결 준비를 마친다.
kernel subprocess가 준비되면 jupyter notebook web server는 이를 감지하고 본격적으로 kernel과 통신을 시작한다.
모든 과정을 살펴봤을 때 jupyter notebook과 kernel은 서로 다른 시스템에서 동작하는게 불가능하지 않지만, kernel은 jupyter notebook application의 subprocess로 작동해야만 하기 때문에 사실상 동일 시스템에서만 가능하다.
동작 중인 kernel에 client 연결
역으로 이미 동작하고 있는 kernel process가 있을때 연결 방법은 존재할까?
python kernel인 ipykernel를 단독으로 실행하면, 앞서 소개한 방법과 다른 동작을 수행한다.
ipykernel은 소켓을 port에 바인딩하고 통신할때 사용할 보안 정보를 생성한 다음 이 정보를 process의 pid를 포함한 kernel-<pid>.json 이
름으로 jupyter_runtime_dir에 저장한다.(참고로 jupyter notebook의 subprocess로 시작할 때는 uuid를 사용) 실제 실행 경과는 다음과 같다.
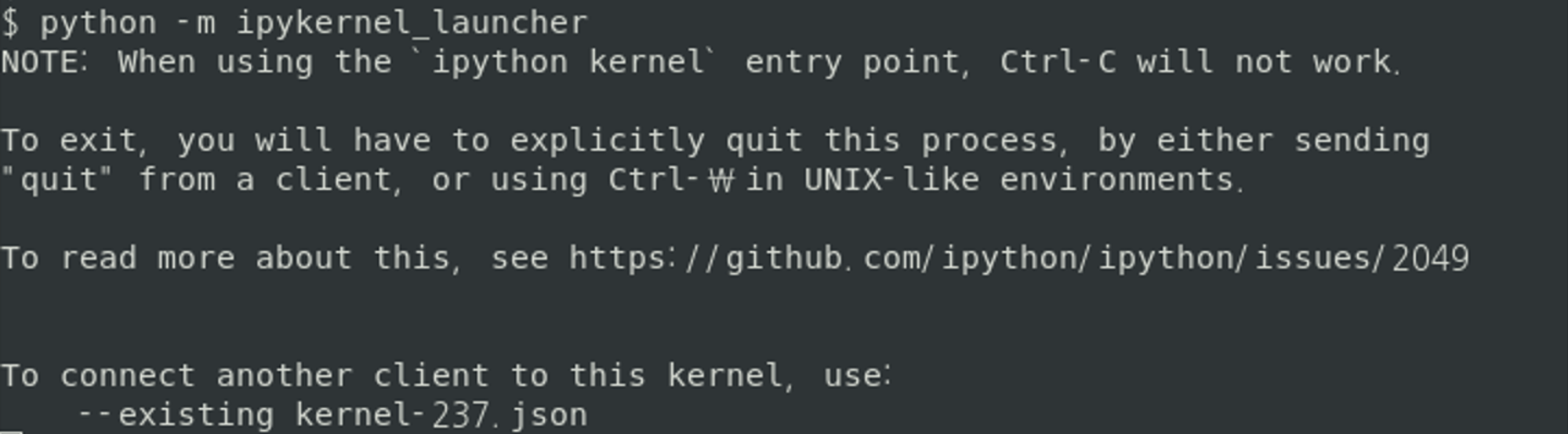
<kernel 단독 실행>
마지막 줄에 client가 이 kernel에 접근하려면 --existing kernel-237.json 옵션을 사용하라는 정보가 나타난다.
이 설명은 jupyter notebook(또는 jupyterlab)이전 부터 존재했던 jupyter console, jupyter qtconsole 등과 같은 front-end application에 해당하는 설명으로, 이 application을 --existing 옵션과 함께 실행하면 kernel-237.json 파일을 읽고 그 정보가 가리키는 원격 kernel에 접속한다.
그러나 jupyter notebook(또는 jupyterlab) 같은 web application은 이 옵션은 지원하지 않기 때문에 이 방법으로 작동하고 있는 kernel에 접근할 수 없다.
III. 가설
지금까지 살펴본 방법들은 application과 kernel이 동일 실행 공간에 있을 때 유효하다.
만약, kernel이 원격에 위치하고 이에 연결해야 한다면 어떤 방법이 있고 그 방법이 제공하는 이점은 어떤것이 있을까?
분석을 하는데 있어 가장 어려운 문제 중의 하나가 notebook 결과의 재현이다.
분석을 위해 여러 라이브러리를 함께 사용하는 환경과 버전에 따라 동작이 조금씩 달라지는 현상 때문에 재현 가능한 환경 구축과 실행은 가장 중요한 작업이 된지 오래다.
이런 문제를 해결하기 위해 언어나 패키지 관리 도구들(pip, conda 등)이 제공하는 가상 환경이라는 기능으로 해결하고 있지만 가상 환경으로 불가능한 경우 별도 시스템에서 구축해야한다.
또, 분산 클러스터에서 동작하는 대량 처리 엔진이나 서비스(GPU, Spark, Hadoop 등)을 사용하려면 그 클러스터에서 직접 실행해야하는 제약 상 원격 kernel는 필수 기능이라고 할 수 있다.
IV. 해결 방법
Jupyter Kernel Gateway
jupyter kernel gateway는 ZeroMQ 메세지 기반의 통신을 표준 http / websocket으로 변환 중계하는 headless web server로, jupyter notebook이 local에서 kernel을 다루는 방법과 동일한 방식으로 원격 host에서 kernel들을 관리한다.
특징
■ 2 mode
•
jupyter-websocket mode : websocket kernel 통신을 위해 Jupyter Notebook server 호환 API 제공
•
notebook-http mode : notebook 파일을 구성한는 cell 각각을 http api로 연결해서 http 요청에 대한 handler로 동작하는 기능 제공
•
사용자 정의 mode 가능
■ options
•
다른 kernel 통신 메커니즘을 제공하기 위해 third party personalities를 plugin 기능 제공
•
공유 authentication token을 설정하고 client에게 요구 - local kernel에서 이미 제공하는 기능
•
브라우저 기반 client service를 위한 CORS headers 설정
•
사용자 정의 기본 URL 설정
•
gateway server가 생성 할 수 있는 kernel instance 제한 수량 설정
•
사전 생성할 kernel instance의 수량 설정
•
요청하지 않을 경우 제공할 기본 kernel language 설정
•
노트북에서 kernel memory를 사전에 채우는 옵션
•
특정 annotation을 포함한 notebook을 HTTP endpoints로 제공
•
notebook-http mode에서 실행할 때 notebook source를 다운로드를 허용하는 옵션
•
notebook-http mode에서 notebook 정의 API를 Swagger specs으로 생성하는 기능
V. 분석결과
실제 사용 사례를 중심으로 원격 kernel 통신과 사용 범위를 확인해보자.
IBM은 자사 메인 프레임에서 데이터 분석을 위해 IzODA( z / OS 용 IBM Open Data Analytics )라고 부르는 개방형 Data 분석 환경을 제공하고 있다.
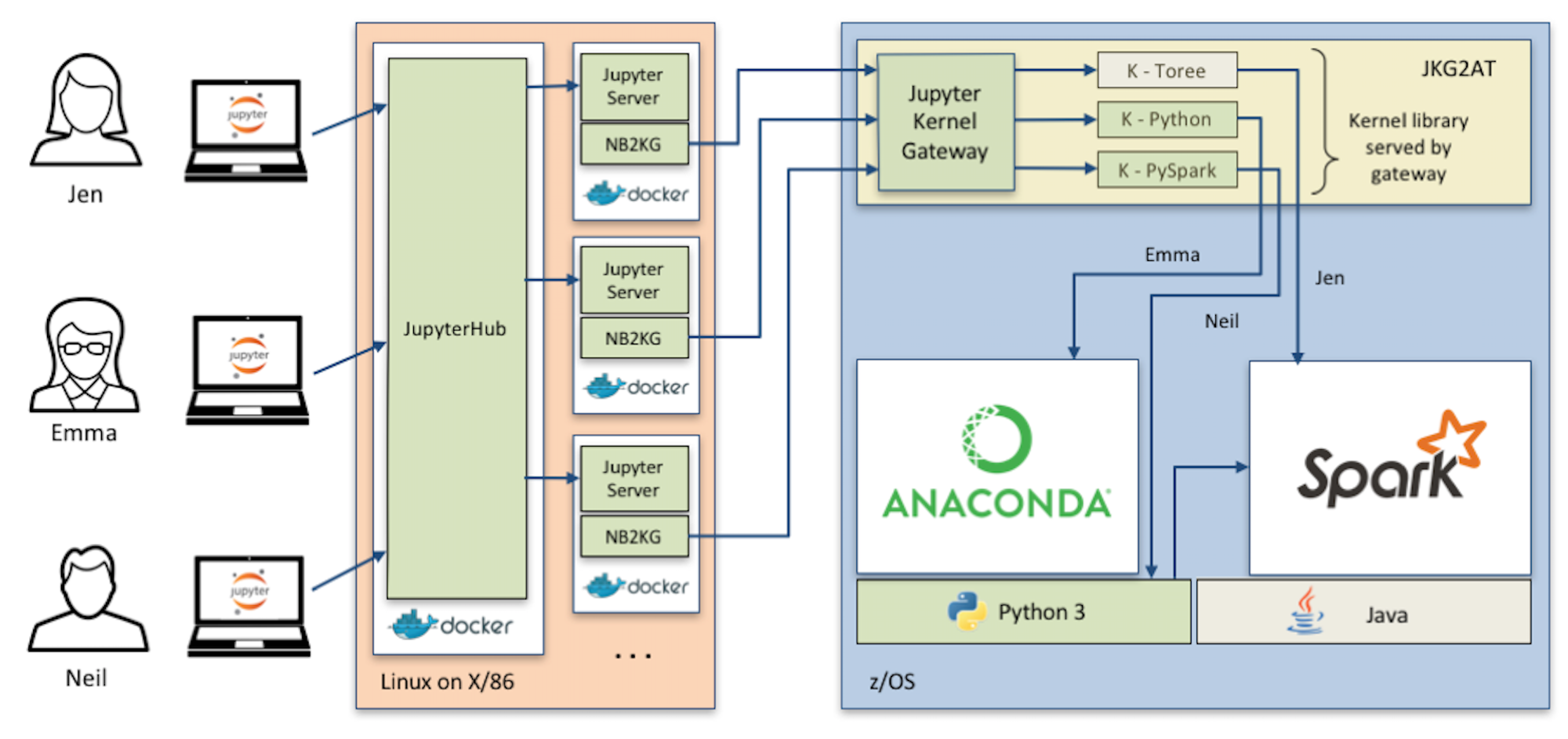
IzODA는 데이터 과학자가 사용할 분석 인터페이스로 jupyter notebook을 내세우면서, jupyter notebook은 linux가 동작하는 x86 서버 위에, kernel은 spark을 운영하는 메인프레임 위에 배치한 아키텍쳐를 제시했다.
이 아키텍처에서 확인할 수 있는 내용은 big data 분산 클러스터(spark 또는 hadoop)의 강력한 처리 능력이 필요하거나, Host의 컴퓨팅 자원(메인프레임)을 여러 client에서 공유해야만 할 때 jupyter kernel gateway가 적절한 해결책이 될 수 다는 점이다.
※ nb2kg
jupyter notebook server extension 프로젝트
jupyter notebook의 server에 jupyter kernel gateway 통신 기능을 추가하기 위해 시작
jupyter notebook v6.0부터 내부 기능으로 흡수되었다.
주의
일반적으로 jupyter notebook은 파일 읽기, 수정, 저장을 처리하고, kernel은 요청받은 code를 실행한다. 그래서 어떤 file을 읽어서 처리하는 code를 실행할 경우 그 file은 kernel이 접근 가능한 공간에 존재해야한다.
그러므로, jupyter kernel gateway를 이용해 kernel과 jupyter notebook을 분리하면 ipynb 파일과 분석 대상 파일도 분리해야한다.
VI. 결론
jupyter notebook은 jupyter kernel gateway api를 사용해서 원격 kernel을 local처럼 연결하고, 제어할 수 있다는 걸 확인했다.
여러 다양한 분석 환경들을 jupyter notebook과 분리해서 독립적으로 제공하고 효율적인 자원 운영도 기대할 수 있지만, 동일 시스템 내부에서 움직이던 패킷이 외부로 나가면서 시스템 복잡도가 높아지고, kernel이 사용할 파일(대부분 분석 대상 data)을 잘 분리해야만 하는 문제 등 반대 급부도 발생하기 때문에 도입을 결정한다면 적용 범위를 신중하게 고려해서 결정해야한다.
VII. 후속연구/차후계획
jupyter kernel gateway는 원격 kernel 실행 기능을 제공하지만 아쉽게도 단일 host에 적합한 구조를 가지고 있다. gateway 의 장애발생에 대비한 HA구성이 미흡하기 때문에 보완 작업을 하거나 다른 솔루션을 조사할 필요가 있다.
【6】 Jupyter Notebook과 Kernel 연결 방식 조사 : kt NexR 기술블로그 ‘21 테크리포트
Reference
•
Cookbook: Connecting to a remote kernel via ssh
•
Jupyter Kernel Gateway : jupyter kernel gateway 문서
•
IBM Open Data Analytics for z/OS (IzODA) : IBM z/OS를 위한 데이타 분석 환경

본 기술블로그에 게재되는 모든 컨텐츠의 저작권은 케이티넥스알(kt NexR)에서 가지고 있으며, 동의 없는 컨텐츠 수정 및 무단 복제는 금하고 있습니다. 컨텐츠(글/사진/영상 등)를 공유하실 경우 반드시 출처를 밝혀주시기 바랍니다. Copyright(c) 2021 kt NexR, Inc. All Rights Reserved.