
.jpg&blockId=c07f0df6-106a-4240-8d2e-840d6c4dd9a6&width=3600)
서론
NDC Altas, Felice 에서 사용되고 있는 Kafka를 k8s(쿠버네티스) 환경에서의 성능을 비교 분석하여 NDC altas 에서 사용중인 kafka의 성능을 분석한다.
또한 성능 테스트 결과를 분석하여 k8s 환경에서 카프카 서비스를 안정적으로 제공하는 것을 목표로 한다.
관련 기술
Apache Kafka
kafka는 LinkedIn에서 개발된 메시지큐 방식 기반, 분산 메시징 시스템 이다.
Kafka 특징
대용량 실시간 로그처리에 특화되어 설계된 메시징 시스템으로 TPS(transactions per second)가 매우 우수하며, 메시지를 메모리에 저장하는 기존 메시징 시스템과는 달리 파일에 저장 (메세지 유실 우려 감소)한다.
기본 메시징 시스템(rabbitMQ, ActiveMQ)에서는 브로커(Broker)가 컨슈머(consumer)에게 메시지를 push해 주는 방식이다.
카프카는 컨슈머(Consumer)가 브로커(Broker)로부터 메시지를 직접 가져가는 PULL 방식으로 동작하여 컨슈머는 자신의 처리 능력만큼의 메시지만 가져와 최적의 성능을 낼 수 있다.
그림1: apache kafka architecture(1)
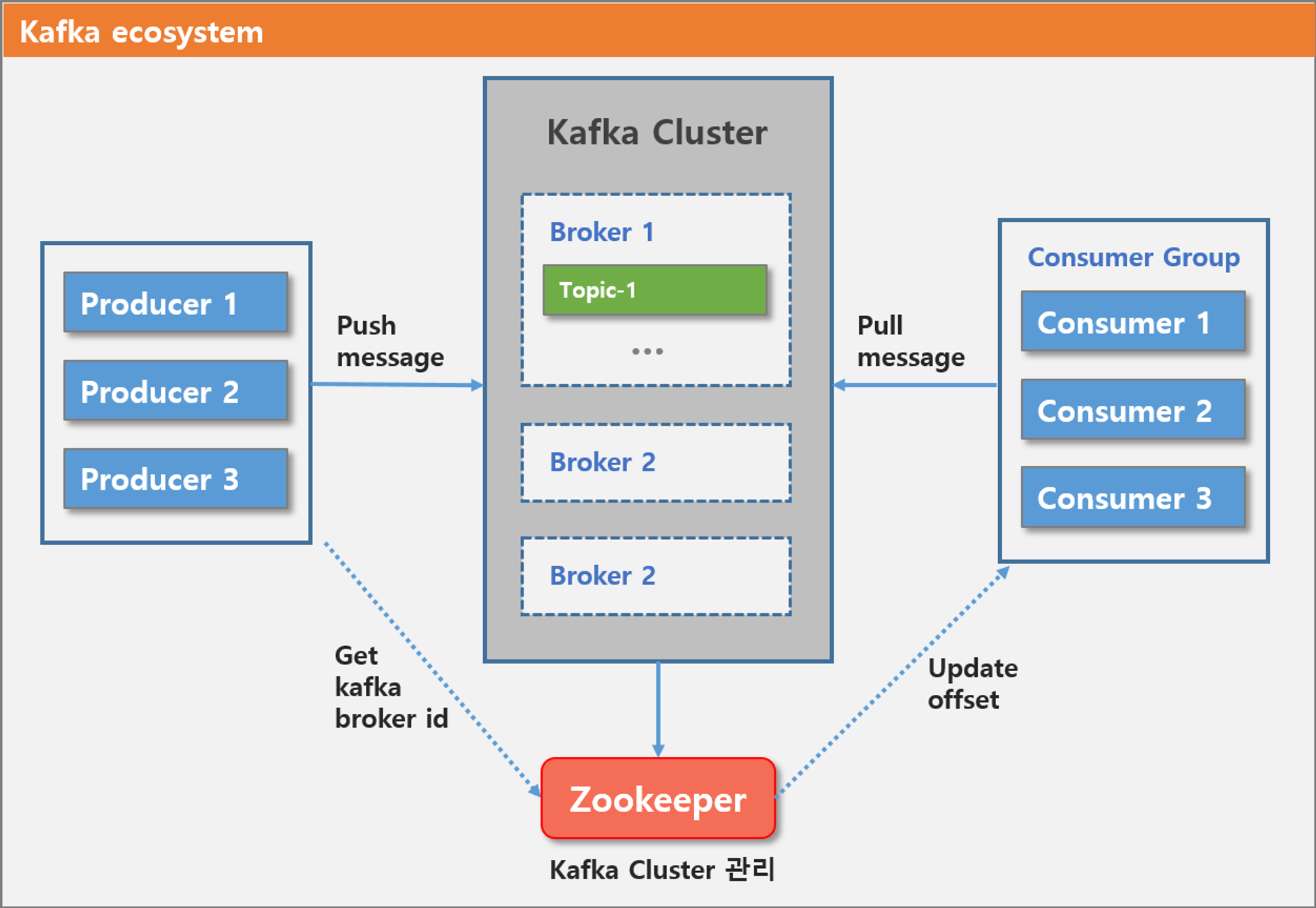
•
브로커(broker) : 카프카 애플리케이션이 설치된 서버 또는 노드
•
프로듀서(producer): 카프카로 메세지를 보내는 역할을 하는 클라이언트로 총칭
•
컨슈머(consumer) : 카프카에서 메세지를 꺼내가는 역할을 하는 클라이언트를 총칭
•
토픽(topic) : 카프카는 메시지 피드들을 토픽으로 구분하고, 각 토픽의 이름은 카프카 내에서 공유
카프카를 사용하는 이유?
카프카는 파일 시스템을 활용한 고성능 디자인이다. 일반적으로 하드디스크는 메모리보다 수백배 느리지만 하드디스크의 순차적 읽기에 대한 성능은 메모리보다 크게 떨어지지 않는다고 한다
카프카 는 Broker의 장애에도 불구하고 연속적으로 안정적인 서비스 제공함으로써 데이터 유실을 방지하며 유연성을 제공한다.
이와 관련된 카프카에 복제본(replication) 과 관련된 개념을 먼저 실험에 앞서 설명하고자 한다.
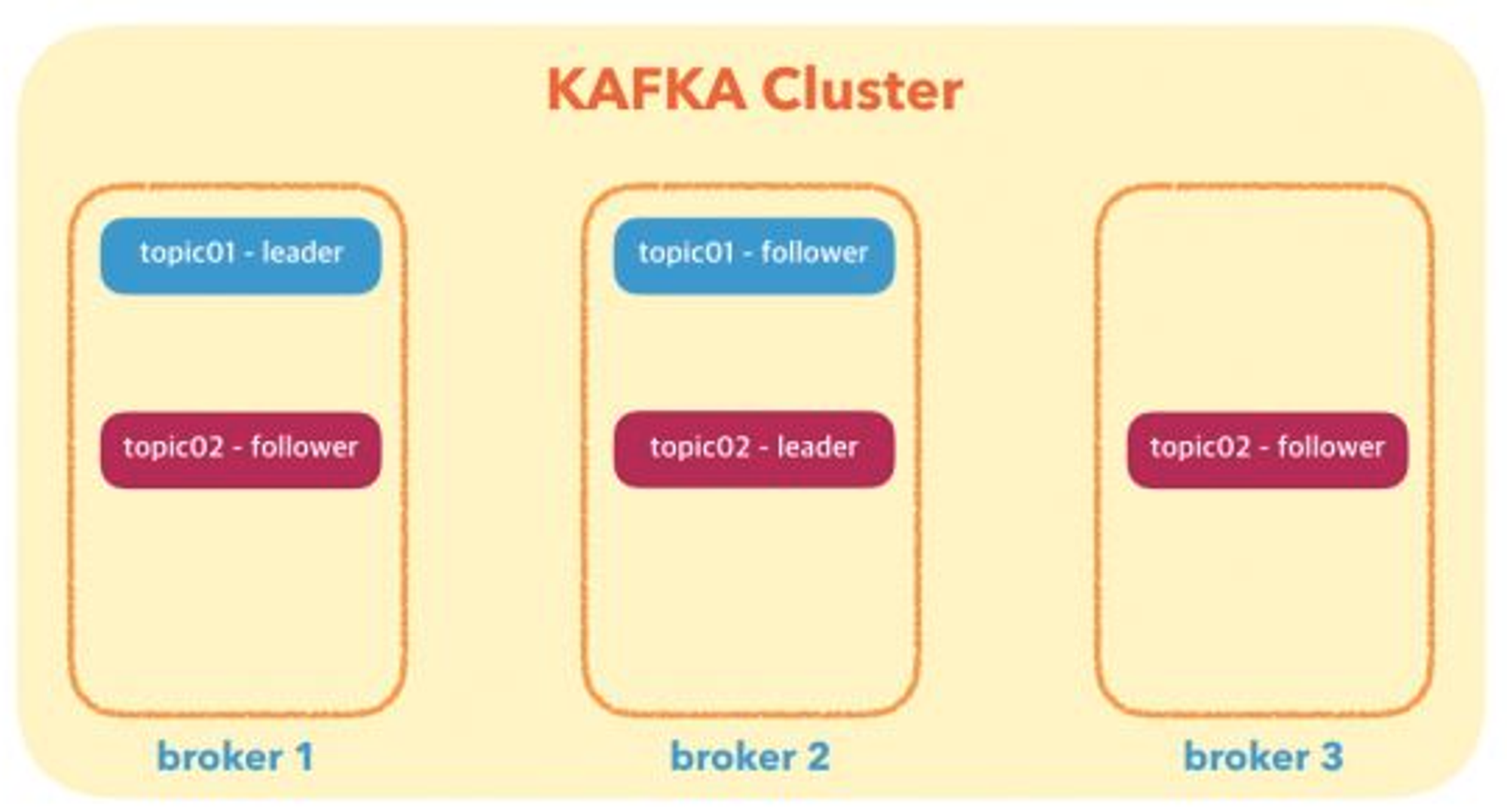
kafka replication factor & leader & follower
kafka에서는 복제본(replication) 수를 임의로 지정하여 topic를 만들 수 있다.
topic의 복제본이 2개이상 있는 경우 하나는 leader, 나머지는 follower라고 표현한다.
그림 2 : Kafka Cluster -1(4)
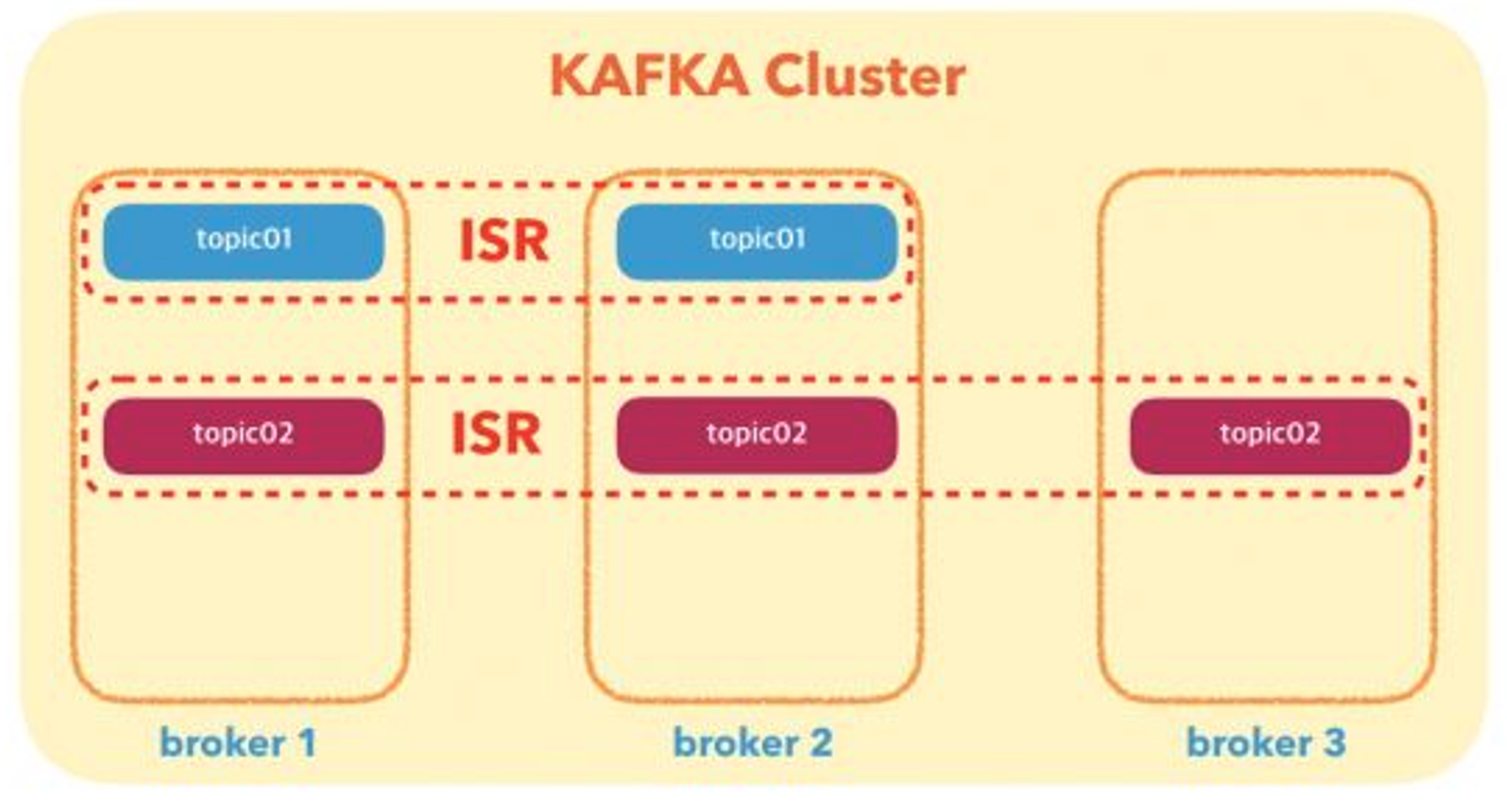
ISR(In Sync Replica)
ISR은 kafka 리더 파티션과 팔로워 파티션이 모두 싱크가 된 상태를 의미한다.
topic를 만들게 되면, topic이 생성되고 옵션으로 replication factor를 설정하면 replication factor 수에 맞추어 위와 같이 ISR이 구성된다.
ISR 그룹의 topic들은 아래와 같이 나누어진다.
•
leader : follower 중에서 자신보다 일정기간 동안 뒤쳐지면 leader가 될 자격이 없다고 판단하여 뒤쳐지는 follower를 ISR에서 제외시킨다.
•
follower : leader와 동일한 데이터 내용을 유지하기 위해서 짧은 주기로 leader로부터 데이터를 가져온다.
•
그림 3 : Kafka Cluster-2 (4)
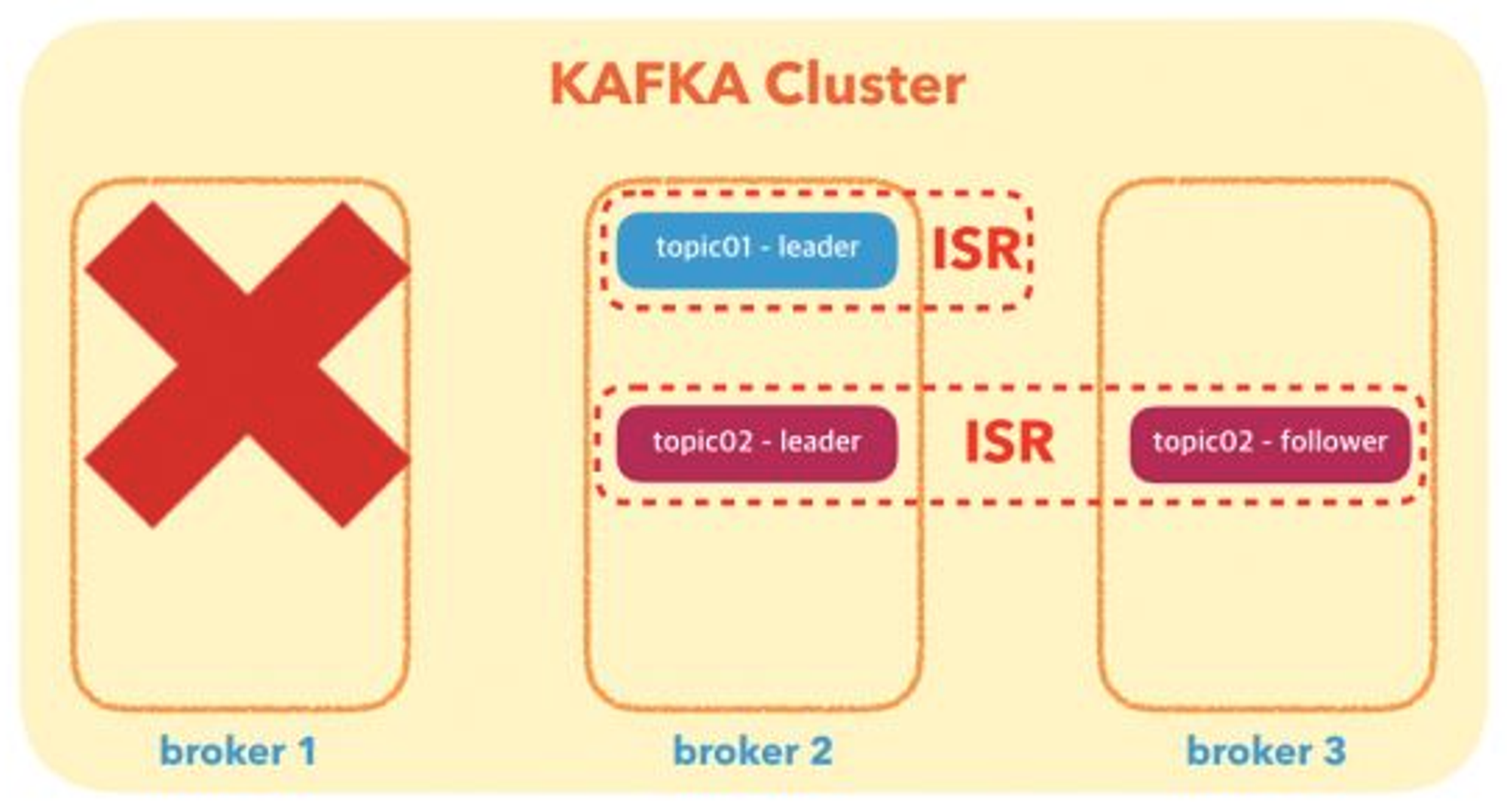
예를 들어 만약 broker1이 down 되었다면,
leader가 down 되거나, leader가 있는 broker가 down 되었을 때, follower 중 하나가 new leader가 되어 broker 하나가 down 되어도 서비스를 지속할수 있도록 할수 있다.
그림 4 : Kafka Cluster-3 (4)
실험준비
실험 목적
이번 실험의 목적은 앞서 설명한 카프카의 복제본을 조절하면서 일반서버환경과 k8s 환경에서 카프카의 성능을 테스트하여 결과를 분석하고자 한다.
카프카의 복제본은 Broker에서 조절하기 때문에 이번 실험에서는 Broker와 중심으로 설정을 변경하며 실험을 진행한다.
Broker 와 관련된 항목은 그림5에서 설명한다.
그림5: apache kafka architecture(2)
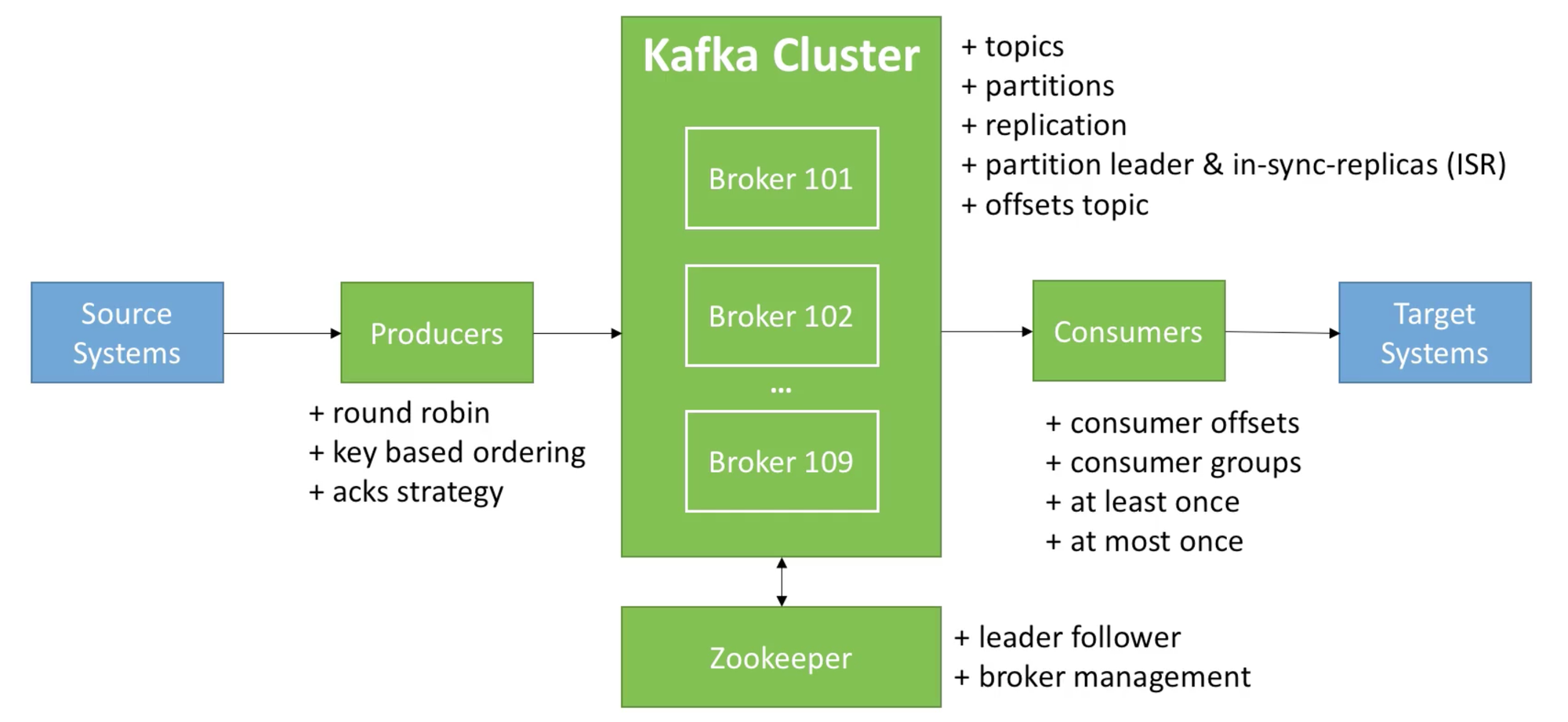
Broker 관련 설정항목은 아래와 같다.
•
topic : kafka에서 특정한 데이터 스트림을 의미
•
replication : 소스 브로커의 메시지를 복제하는 데 사용되는 복제본 수 (이 값을 늘리면 브로커의 I/O 조작에서 병렬 처리가 늘어날 수 있음)
•
partition : 메세지를 저장하는 물리적인 파일를 의미하며, 한 개의 토픽은 한 개 이상의 파티션으로 구성. 파티션은 메시지 추가만 가능한 파일(append-only)
•
ISR(In-sync-replicas) : 프로듀서가 acks=all로 설정하여 메시지를 보낼 때, write를 성공하기 위한 최소 복제본의 수를 의미 (min.insync.replicas 옵션으로 설정)
•
offsets topic : 파티션내 각 메시지의 저장된 상대적 위치
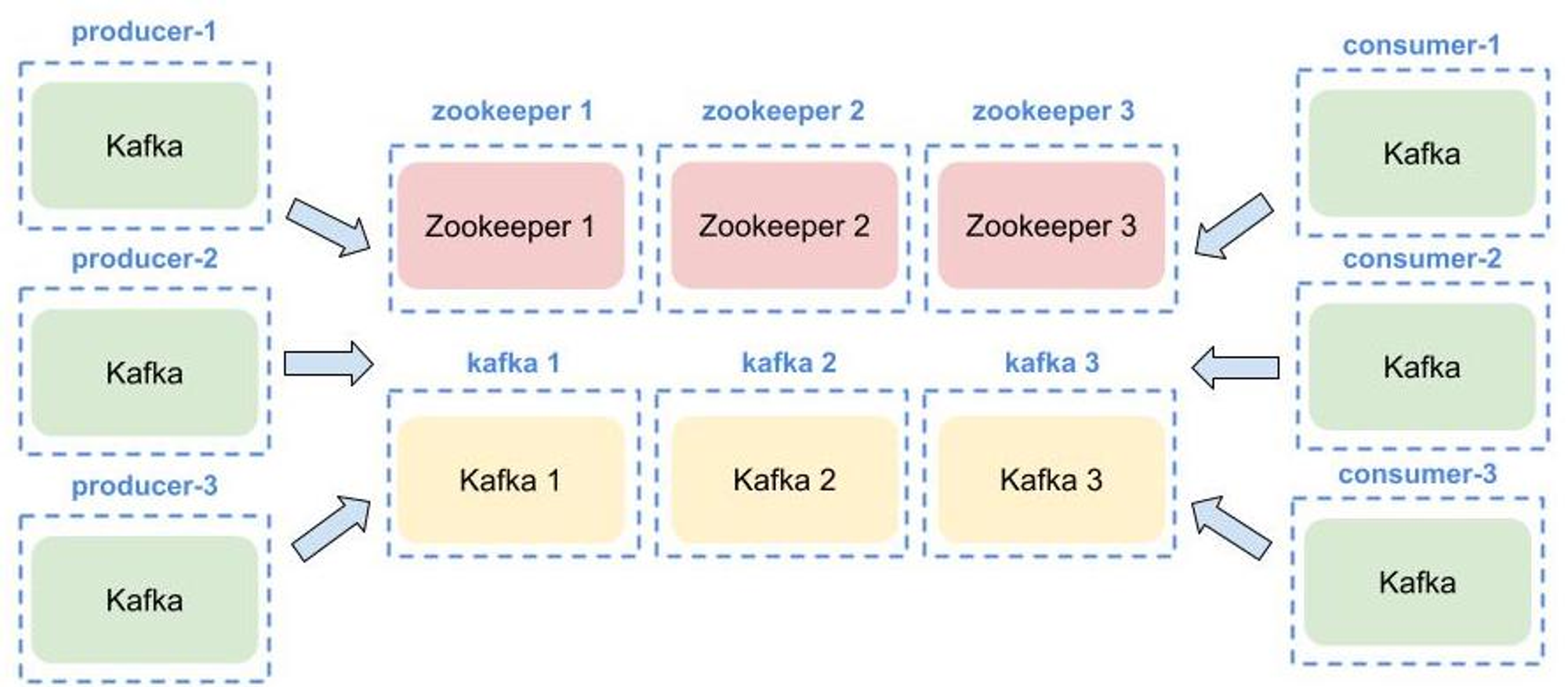
실험 환경
실험을 진행 함에 있어 KT NexR의 제품인 NE Governance, NE Flowpipe의 Kafka 와 동일한 버전으로 일반서버환경와 k8s 환경에서 OSS를 설치하여 실험을 진행한다.
표1: 일반서버환경에 사용된 HW 및 SW 사양
서버 | demo1,2,3,4,5 |
vCPU | 32 core |
Memory | 377G |
DIsk | SDD 1TB |
OS | Ubuntu 22.04.1 |
Zookeeper | 3.6.3 |
Kafka | 2.8.2 |
그림1: 일반서버환경 아키텍처 구성
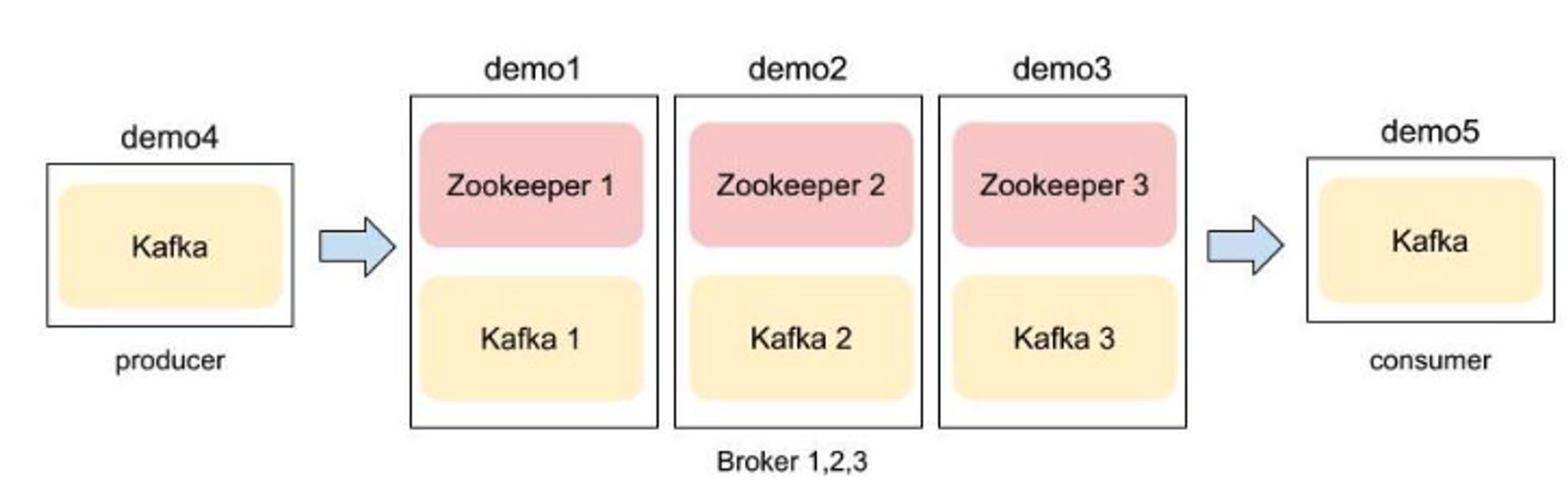
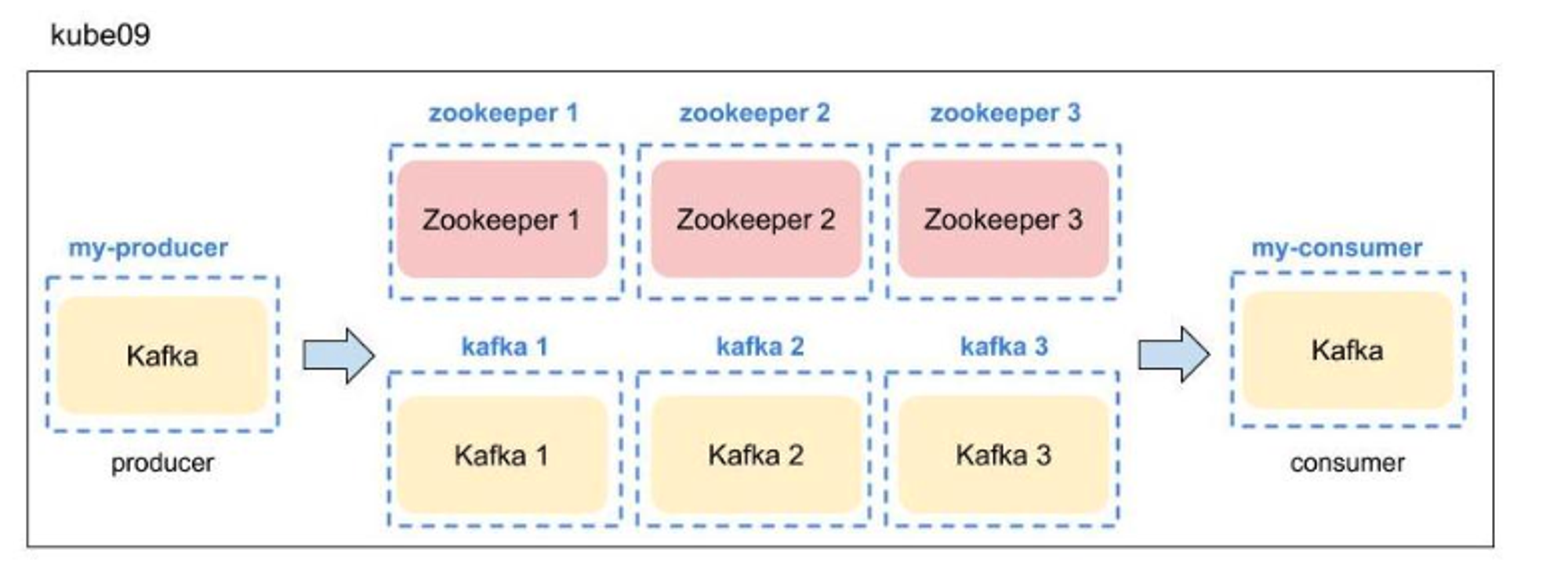
표2: k8s 환경에 사용된 HW 및 SW 사양
서버 | kube09 cluster |
vCPU | 20 core |
Memory | 256G |
DIsk | HDD 4TB |
OS | centos 7.9 |
Zookeeper | 3.6.3 |
Kafka | 2.8.1 |
그림2: k8s서버 환경 아키텍처
실험 도구
카프카는 성능 테스트를 기본적으로 제공하고 있어, 현재 구축한 카프카 클러스터의 성능을 확인할 수 있다.
해당 쉘 파일은 카프카를 설치한 하위 디렉토리 bin에 있다. (path : kafka/bin)
이번 실험에서는 Kafka 에서 제공하는 테스트용 스크립트를 사용하였으며 대표적으로 같은 쉘 파일을 실험에 사용하였다.
•
kafka-producer-perf-test.sh(프로듀서 속도측정)
•
kafka-consumer-perf-test.sh(컨슈머 속도측정)
•
kafka-topics.sh (토픽생성)
실험 셋팅
시험방법은 3.2 실험도구에서 설명한 카프카에서 기본적으로 제공하고 있는 쉘 파일을 사용하여 아래와같이 진행하였다.
•
토픽생성
토픽을 생성할때 복제 개수는 3개이며 파티션도 3개로 토픽을 생성했다.
$ bin/kafka-topics.sh --create --bootstrap-server \
broker-server1:9092,broker-server2:9092,broker-server3:9092 \
--replication-factor 3 \
--partitions 3 \
--topic bmt |
•
Producer 메세지 전송 & 성능측정
아래의 명령어를 통해 메세지( record-size:200 x records :2000000 = 약 400MB)를 전송한다.
$ bin/kafka-producer-perf-test.sh \
--topic bmt \
--throughput -1 \
--num-records 2000000 \
--record-size 2000 \
--producer-props ack=1 bootstrap.servers=broker-server1:9092,broker-server2:9092,broker-server3:9092 |
•
Consumer 메세지 수집 & 성능측정
아래의 명령어를 통해 메세지( record-size:200 x records :2000000 = 약 400MB)를 Broker 로 부터 전달 받는다.
$ bin/kafka-consumer-perf-test.sh \--topic bmt \--broker-list broker-server1:9092,broker-server2:9092,broker-server3:9092, \--messages 2000000 \ |
실험수행 및 결과분석
일반서버환경 vs k8s 환경 분석
4.1절의 실험은 일반서버환경와 k8s환경에서 구축한 Kafka 환경(NDC altas chart 적용)에서 현재 설정 상태에서 실험을 진행한다.
Kafka 성능을 토픽을 replication 1,2,3 순으로 생성하여 약 400MB 의 데이터를 전송한 속도 측정을 진행하였으며 측정하였고 측정치는 결과는 다음과 같다.
토픽생성은 아래같이 생성하였으며, 실험 1,2,3,4 에서도 동일하게 토픽생성하여 실험을 진행하였다.
-- replication 1
root@demo04:~/kafka/bin# ./kafka-topics.sh --describe --topic original --bootstrap-server demo01:9092
Topic: original TopicId: jHPQPwzrSk-siePEf_JNkQ PartitionCount: 3 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: original Partition: 0 Leader: 1 Replicas: 1 Isr: 1
Topic: original Partition: 1 Leader: 2 Replicas: 2 Isr: 2
Topic: original Partition: 2 Leader: 3 Replicas: 3 Isr: 3
-- replication 2
root@demo04:~/kafka/bin# ./kafka-topics.sh --describe --topic local1 --bootstrap-server demo01:9092
Topic: local1 TopicId: LsBYY7RnTJq8PE8FXbjG_g PartitionCount: 3 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: local1 Partition: 0 Leader: 3 Replicas: 3,1 Isr: 3,1
Topic: local1 Partition: 1 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: local1 Partition: 2 Leader: 2 Replicas: 2,3 Isr: 2,3
-- replication 3
root@demo04:~/kafka/bin# ./kafka-topics.sh --describe --topic local2 --bootstrap-server demo01:9092
Topic: local2 TopicId: tzitEUYuT6qb2CKHwhVDrw PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: local2 Partition: 0 Leader: 2 Replicas: 2,1,3 Isr: 2,1,3
Topic: local2 Partition: 1 Leader: 3 Replicas: 3,2,1 Isr: 3,2,1
Topic: local2 Partition: 2 Leader: 1 Replicas: 1,3,2 Isr: 1,3,2 |
링크1: 4.1절 실험결과 Sheet
해당 결과를 그래프로 표현하면 다음 그림3와 같다.
그림3: 일반서버 환경 vs k8s 환경: replica 수에 따른 producer, consumer 성능 (단위: mb/sec)
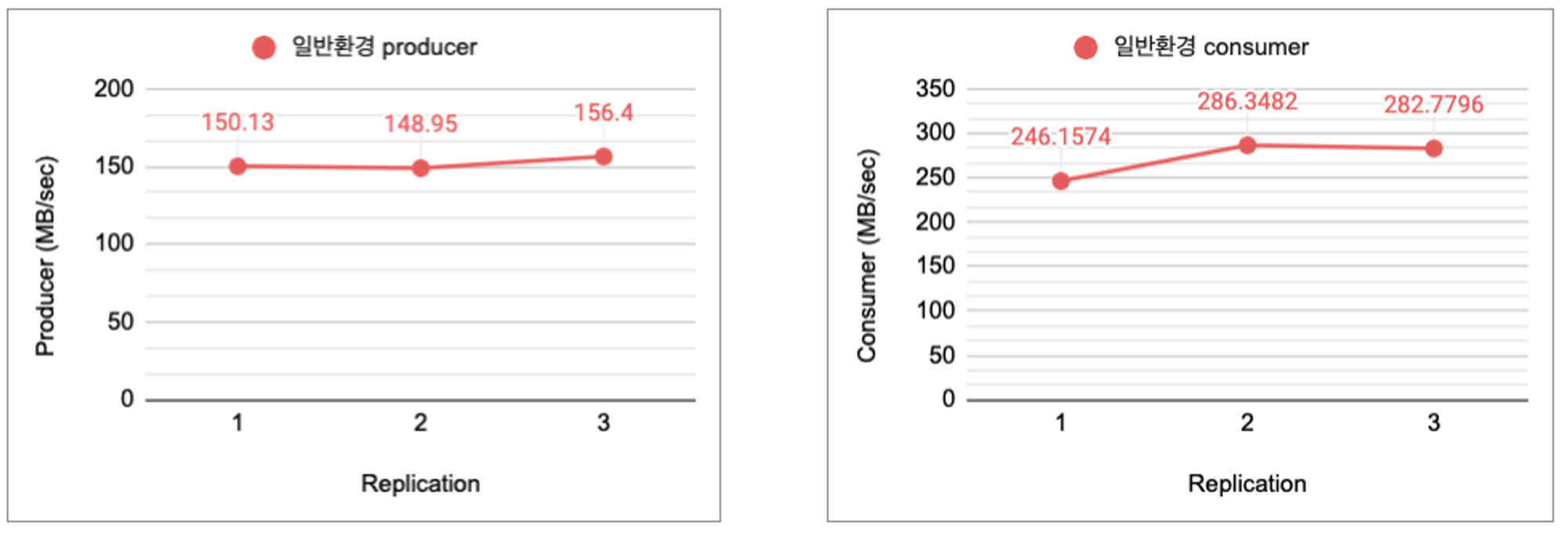
그림4: k8s환경 replica 수에 따른 producer, consumer 성능 (단위: mb/sec)
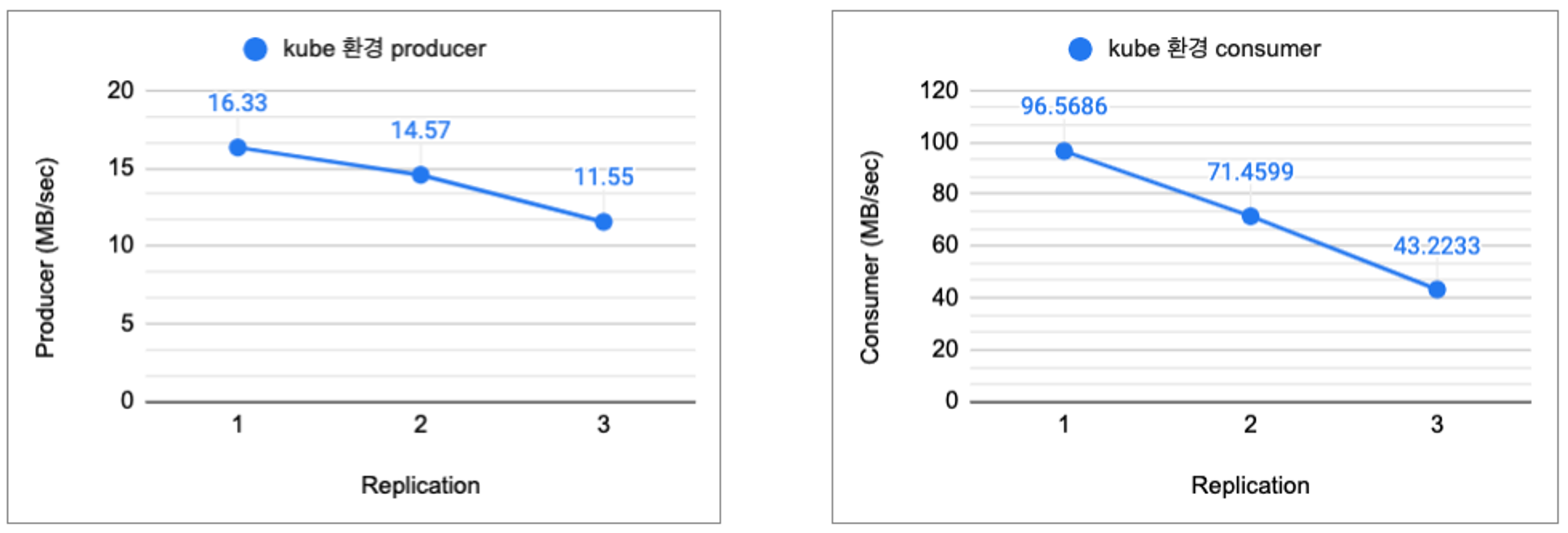
k8s 환경에서 replication factor를 증가하면 성능이 오히려 감소한다.
일반 환경에서는 replication factor를 증가하여도 성능이 일정함을 유지한다.
왜 k8s환경에서는 성능이 감소하는가?
•
리소스가 부족해서 충분히 분산처리가 안된다고 가정하여 다음 실험에서는 리소스를 늘려서 성능테스트를 진행하기로 한다.
k8s 환경의 리소스 증가시킨 경우
이번 4.2절 실험에서는 4.1절의 실험과 동일하게 수행하되 k8s 환경의 Kafka 의 Helm Chart에서 아래와 같이 리소스를 확장하여 측정한다.
토픽을 replication 1,2,3 순으로 생성하여 약 400MB 의 데이터를 전송한 속도 측정을 진행하였으며 측정하였고 측정치는 결과는 다음과 같다.
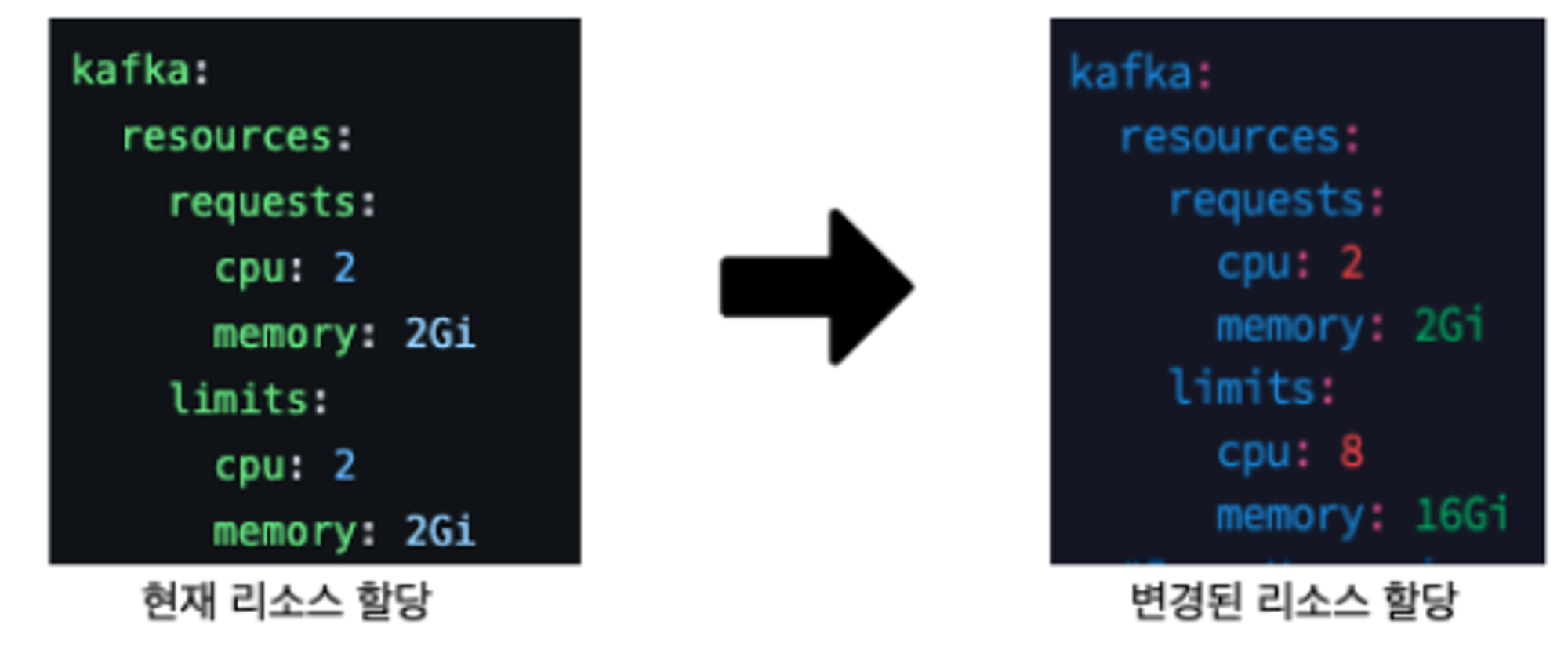
-- k8s환경 변경된 리소스 (cpu 8 core, memory 16Gi)
-- producer 성능
[summer@kube09 ~]$ kubectl exec -it my-producer -n summer-kafka -- kafka-producer-perf-test.sh --topic test1 --throughput -1 --num-records 200000 --record-size 2000 --producer-props ack=1 bootstrap.servers=summer2-kafka:9092
[2022-12-21 05:32:15,134] WARN The configuration 'ack' was supplied but isn't a known config. (org.apache.kafka.clients.producer.ProducerConfig)
200000 records sent, 45610.034208 records/sec (86.99 MB/sec), 294.09 ms avg latency, 623.00 ms max latency, 312 ms 50th, 518 ms 95th, 588 ms 99th, 619 ms 99.9th.
[summer@kube09 ~]$ kubectl exec -it my-producer -n summer-kafka -- kafka-producer-perf-test.sh --topic test3 --throughput -1 --num-records 200000 --record-size 2000 --producer-props ack=1 bootstrap.servers=summer2-kafka:9092
[2022-12-21 05:34:03,092] WARN The configuration 'ack' was supplied but isn't a known config. (org.apache.kafka.clients.producer.ProducerConfig)
200000 records sent, 43374.539146 records/sec (82.73 MB/sec), 308.75 ms avg latency, 760.00 ms max latency, 293 ms 50th, 631 ms 95th, 703 ms 99th, 756 ms 99.9th.
[summer@kube09 ~]$ kubectl exec -it my-producer -n summer-kafka -- kafka-producer-perf-test.sh --topic test4 --throughput -1 --num-records 200000 --record-size 2000 --producer-props ack=1 bootstrap.servers=summer2-kafka:9092
[2022-12-21 05:36:39,481] WARN The configuration 'ack' was supplied but isn't a known config (org.apache.kafka.clients.producer.ProducerConfig)
197920 records sent, 39584.0 records/sec (75.50 MB/sec), 346.8 ms avg latency, 1253.0 ms max latency.
200000 records sent, 39385.584876 records/sec (75.12 MB/sec), 349.39 ms avg latency, 1253.00 ms max latency, 219 ms 50th, 960 ms 95th, 1217 ms 99th, 1245 ms 99.9th.
-- consumer 성능
[summer@kube09 ~]$ kubectl exec -it my-consumer -n summer-kafka -- kafka-consumer-perf-test.sh --topic test1 --broker-list summer2-kafka:9092 --messages 200000
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2022-12-21 05:32:24:045, 2022-12-21 05:32:25:863, 381.7902, 210.0056, 200168, 110103.4103, 491, 1327, 287.7092, 150842.5019
[summer@kube09 ~]$ kubectl exec -it my-consumer -n summer-kafka -- kafka-consumer-perf-test.sh --topic test3 --broker-list summer2-kafka:9092 --messages 200000
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2022-12-21 05:34:19:190, 2022-12-21 05:34:20:916, 381.4697, 221.0137, 200000, 115874.8552, 463, 1263, 302.0346, 158353.1275
[summer@kube09 ~]$ kubectl exec -it my-consumer -n summer-kafka -- kafka-consumer-perf-test.sh --topic test4 --broker-list summer2-kafka:9092 --messages 200000
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2022-12-21 05:36:49:630, 2022-12-21 05:36:51:275, 381.9313, 232.1771, 200242, 121727.6596, 415, 1230, 310.5133, 162798.3740 |
해당 결과 값을 그래프로 표현하면 다음 그림 4과 같다.
그림4: k8s환경(defult) vs k8s 환경(리소스증가) : replica 수에 따른 producer, consumer 성능 (단위: mb/sec)
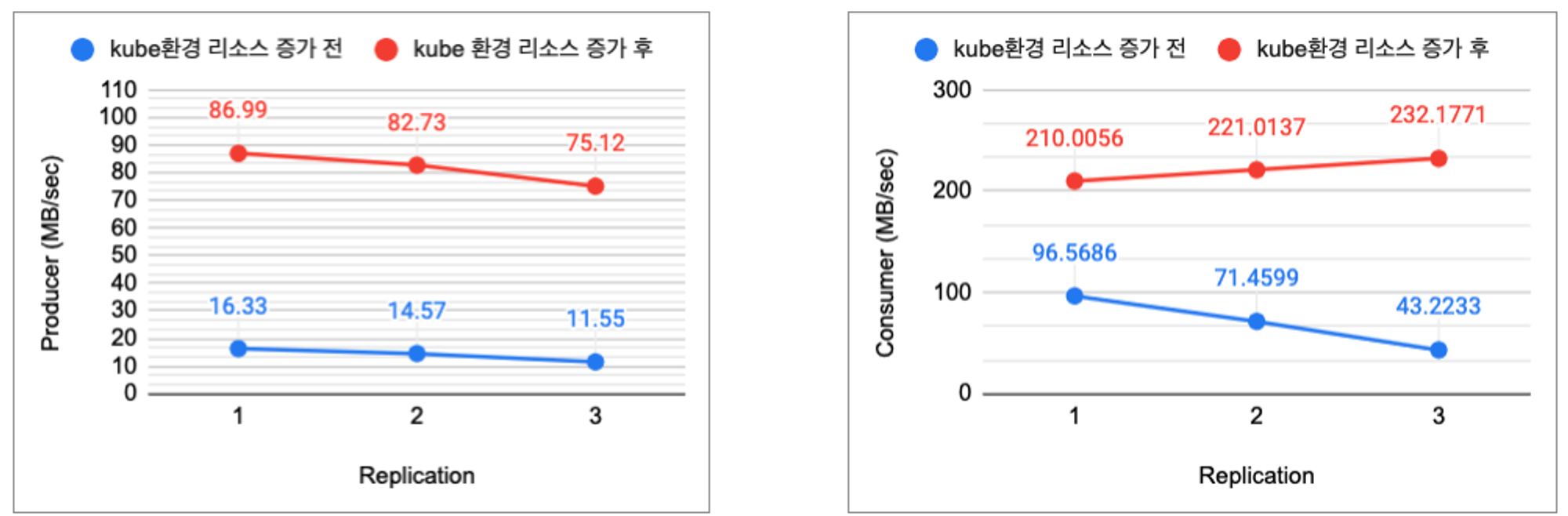
리소스(CPU, Memory) 를 증가함에따라 성능이 레프리카 1,2,3에 따라 약 432%, 467%, 550% 비약적으로 증가하지만 일반서버환경에 대비하여 충분히 증가 하지는 못했다.
왜 일반서버 환경 대비 충분히 증가하지 않는지 아래와 같이 예상하여 추가 실험을 진행하기로 했다.
•
다른설정 (쓰레드) 설정이 충분히 뒷받침되지 못해서
•
리소스(CPU, Memory) 를 증가를 시켰지만 I/O 리소스(디스크, 네크워크)는 그대로이기 때문
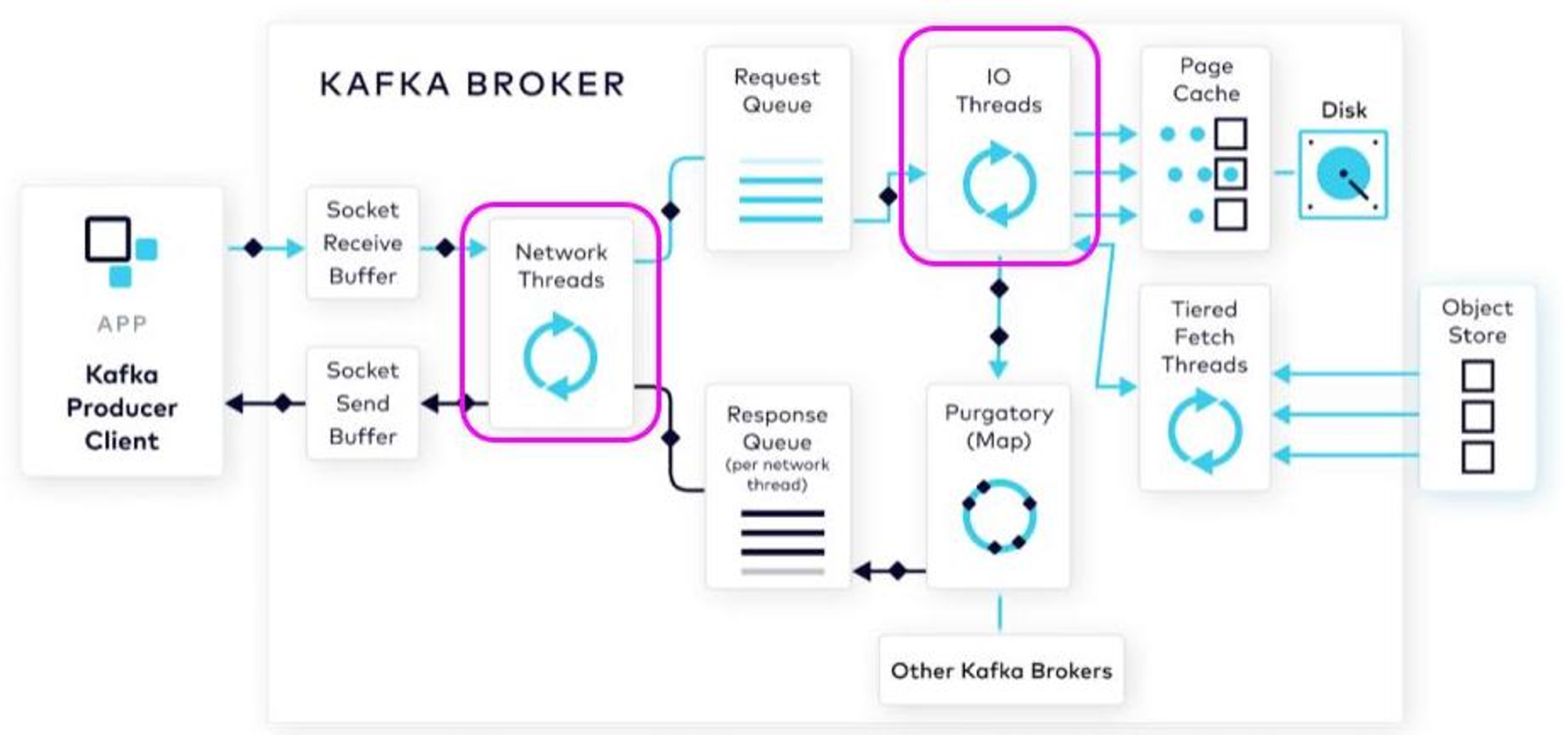
Network and I/O Threads 증가
이번 4.3절 실험에서는 4.1절의 실험과 동일하게 수행하되 k8s 환경의 Kafka 에서 I/O Threads를 아래와 같이 증가시켜 결과값을 측정한다.
•
num.network.threads : 네트워크 요청 처리(즉, 요청 수신 및 응답 전송)에 사용되는 스레드 수 ( 3 → 6)
•
num.io.threads: 브로커가 request 대기열의 request를 처리하는 데 사용하는 스레드 수를 지정 (disk I/O가 포함될수 있다.) (8 → 16)
그림5: Kafka Broker 내부 구조 (5)
토픽을 replication 1,2,3 순으로 생성하여 약 400MB 의 데이터를 전송한 속도 측정을 진행하였으며 측정하였고 측정치는 결과는 다음과 같다.
-- k8s환경 변경된 리소스 (cpu 8 core, memory 16Gi)
-- producer 성능
[2022-12-26 08:49:06,496] WARN The configuration 'ack' was supplied but isn't a known config. (org.apache.kafka.clients.producer.ProducerConfig)
200000 records sent, 46674.445741 records/sec (89.02 MB/sec), 284.22 ms avg latency, 601.00 ms max latency, 267 ms 50th, 537 ms 95th, 592 ms 99th, 600 ms 99.9th.
[summer@kube09 kafka]$ kubectl exec -it my-producer -n summer-kafka -- kafka-producer-perf-test.sh --topic kube2 --throughput -1 --num-records 200000 --record-size 2000 --producer-props ack=1 bootstrap.servers=summer2-kafka:9092
[2022-12-26 08:46:56,426] WARN The configuration 'ack' was supplied but isn't a known config. (org.apache.kafka.clients.producer.ProducerConfig)
200000 records sent, 45300.113250 records/sec (86.40 MB/sec), 299.91 ms avg latency, 643.00 ms max latency, 302 ms 50th, 510 ms 95th, 605 ms 99th, 640 ms 99.9th.
[2022-12-26 08:45:00,287] WARN The configuration 'ack' was supplied but isn't a known config. (org.apache.kafka.clients.producer.ProducerConfig)
200000 records sent, 42016.806723 records/sec (80.14 MB/sec), 317.90 ms avg latency, 741.00 ms max latency, 332 ms 50th, 629 ms 95th, 715 ms 99th, 739 ms 99.9th.
-- consumer 성능
[summer@kube09 kafka]$ kubectl exec -it my-consumer -n summer-kafka -- kafka-consumer-perf-test.sh --topic kube1 --broker-list summer2-kafka:9092 --messages 200000
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2022-12-26 08:49:14:743, 2022-12-26 08:49:16:484, 381.8130, 219.3067, 200180, 114979.8966, 501, 1240, 307.9137, 161435.4839
[summer@kube09 kafka]$ kubectl exec -it my-consumer -n summer-kafka -- kafka-consumer-perf-test.sh --topic kube2 --broker-list summer2-kafka:9092 --messages 200000
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2022-12-26 08:47:10:472, 2022-12-26 08:47:12:402, 381.8302, 197.8395, 200189, 103724.8705, 555, 1375, 277.6947, 145592.0000
[summer@kube09 kafka]$ kubectl exec -it my-consumer -n summer-kafka -- kafka-consumer-perf-test.sh --topic kube3 --broker-list summer2-kafka:9092 --messages 200000
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2022-12-26 08:45:12:679, 2022-12-26 08:45:14:477, 381.8130, 212.3543, 200180, 111334.8165, 473, 1325, 288.1608, 151079.2453 |
해당 결과 값을 그래프로 표현하면 다음 그림 6과 같다.
그림6: 일반서버 환경 replica 수에 따른 producer, consumer 성능 (단위: mb/sec)
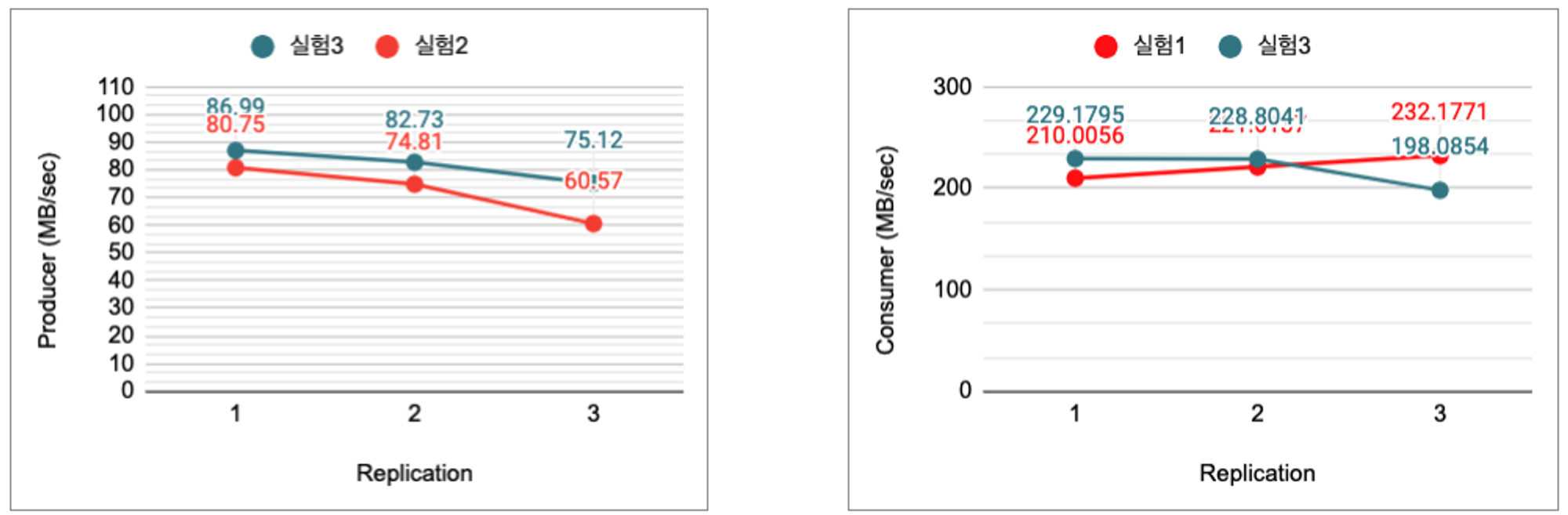
I/O Threads를 이전보다 2배정도 증가시킨 결과,
•
레플리카 수가 각각 1,2,3 인경우 약 7.7% , 10.58%, 14.55% 의 성능향상을 확인할수 있었다.
•
Producer 속도에서는 약 10% 향상을 보이며 성능 안정성을 위해서는 튜닝이 필요할 것으로 보인다.
•
Consumer의 경우 속도 차이가 거의 없는 수준이었다.
ceph에서 Local Storage (HDD) 로 파일시스템을 변경한 경우
이번 4.4절 실험에서는 4.1절의 실험과 동일하게 수행하되 k8s 환경의 Kafka 에서 사용하는 스토리지를 S3 ceph 에서 HDD local storage로 변경하여 측정한다.
토픽을 replication 1,2,3 순으로 생성하여 약 400MB 의 데이터를 전송한 속도 측정을 진행하였으며 측정하였고 측정치는 결과는 다음과 같다.
-- k8s환경 변경된 리소스 (cpu 8 core, memory 16Gi)
-- producer 성능
[summer@kube09 kafka-test]$ kubectl exec -it my-producer -n summer-kafka -- kafka-producer-perf-test.sh --topic volume1 --throughput -1 --num-records 200000 --record-size 2000 --producer-props ack=1 bootstrap.servers=summer2-kafka:9092
[2022-12-27 02:14:41,514] WARN The configuration 'ack' was supplied but isn't a known config. (org.apache.kafka.clients.producer.ProducerConfig)
200000 records sent, 45537.340619 records/sec (86.86 MB/sec), 302.30 ms avg latency, 570.00 ms max latency, 330 ms 50th, 490 ms 95th, 543 ms 99th, 569 ms 99.9th.
[summer@kube09 kafka-test]$ kubectl exec -it my-producer -n summer-kafka -- kafka-producer-perf-test.sh --topic volume2 --records 200000 --record-size 2000 --producer-props ack=1 bootstrap.servers=summer2-kafka:9092
[2022-12-27 02:09:38,082] WARN The configuration 'ack' was supplied but isn't a known config. (org.apache.kafka.clients.producer.ProducerConfig)
200000 records sent, 44189.129474 records/sec (84.28 MB/sec), 305.59 ms avg latency, 479.00 ms max latency, 307 ms 50th, 418 ms 95th, 456 ms 99th, 476 ms 99.9th.
[summer@kube09 ~]$ kubectl exec -it my-producer -n summer-kafka -- kafka-producer-perf-test.sh --topic volume3 --throughput -1 --num-records 200000 --record-size 2000 --producer-props ack=1 bootstrap.servers=summer2-kafka:9092
[2022-12-27 03:12:55,561] WARN The configuration 'ack' was supplied but isn't a known config. (org.apache.kafka.clients.producer.ProducerConfig)
200000 records sent, 48792.388387 records/sec (93.06 MB/sec), 267.94 ms avg latency, 550.00 ms max latency, 270 ms 50th, 446 ms 95th, 540 ms 99th, 549 ms 99.9th.
-- consumer 성능
[summer@kube09 kafka-test]$ kubectl exec -it my-consumer -n summer-kafka -- kafka-consumer-perf-test.sh --topic volume1 --broker-list summer2-kafka:9092 --messages 200000
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2022-12-27 02:14:58:403, 2022-12-27 02:15:00:104, 381.8130, 224.4639, 200180, 117683.7155, 465, 1236, 308.9102, 161957.9288
[summer@kube09 kafka-test]$ kubectl exec -it my-consumer -n summer-kafka -- kafka-consumer-perf-test.sh --topic volume2 -kafka:9092 --messages 200000
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2022-12-27 02:10:40:735, 2022-12-27 02:10:42:450, 382.1239, 222.8128, 200343, 116818.0758, 484, 1231, 310.4175, 162748.1722
[summer@kube09 ~]$ kubectl exec -it my-consumer -n summer-kafka -- kafka-consumer-perf-test.sh --topic volume3 --broker-list summer2-kafka:9092 --messages 200000
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec |
해당 결과 값을 그래프로 표현하면 다음 그림 6과 같다.
그림6: 일반서버 환경 replica 수에 따른 producer, consumer 성능 (단위: mb/sec)
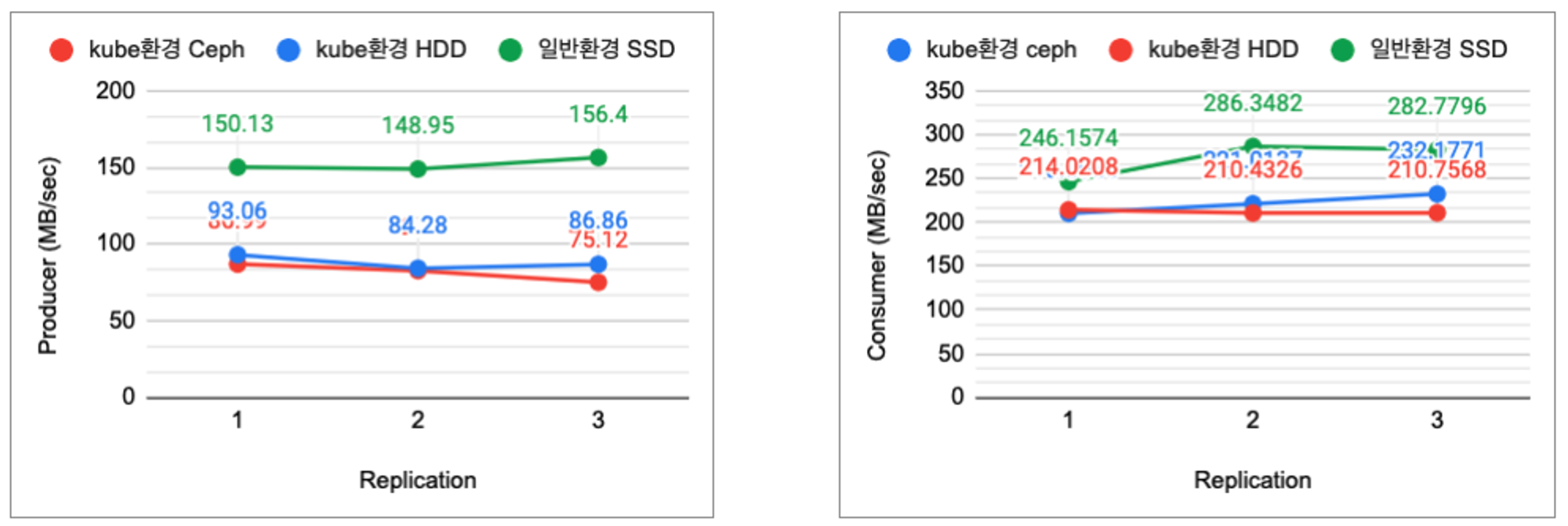
ceph storage에서 현재 kube 환경에서 사용가능한 HDD local storage로 변경한 경우.
•
안정성을 높이기 위해 복제본 수를 증가 시켰을 경우, 성능이 복제본 개수 1,2,3 순으로 약 6.9%,1.8%,13% 상승한것을 확인할수 있다.
•
k8s 환경실험의 경우 물리적인 HDD를 한대에 복제본들이 할당되었기 때문에 성능향상의 제약이 있는것으로 추정할 수 있다.
•
일반환경에서 SSD를 사용한 경우를 비교해보았을때 큰 성능 차이를 보였기 때문에 volum storage를 별도의 SSD를 사용할 경우 더 많은 성능 향상이 기대된다.
Producer & Consumer 분산 테스트
이번 실험에서는 producer, consumer 를 추가로 생성하여 동시에 분산처리를 하는 경우 어느정도의 성능을 보이는지 실험을 진행해보았다.
토픽을 replication 1,2,3 순으로 생성하여 약 400MB 의 데이터를 전송한 속도 측정을 진행하였으며 측정하였고 측정치는 결과는 다음과 같다.
링크2: 4.5절 실험결과 Sheet
해당 결과 값을 그래프로 표현하면 다음 그림 6과 같다.
그림7: 일반서버 환경 replica 수에 따른 producer, consumer 성능 (단위: mb/sec)
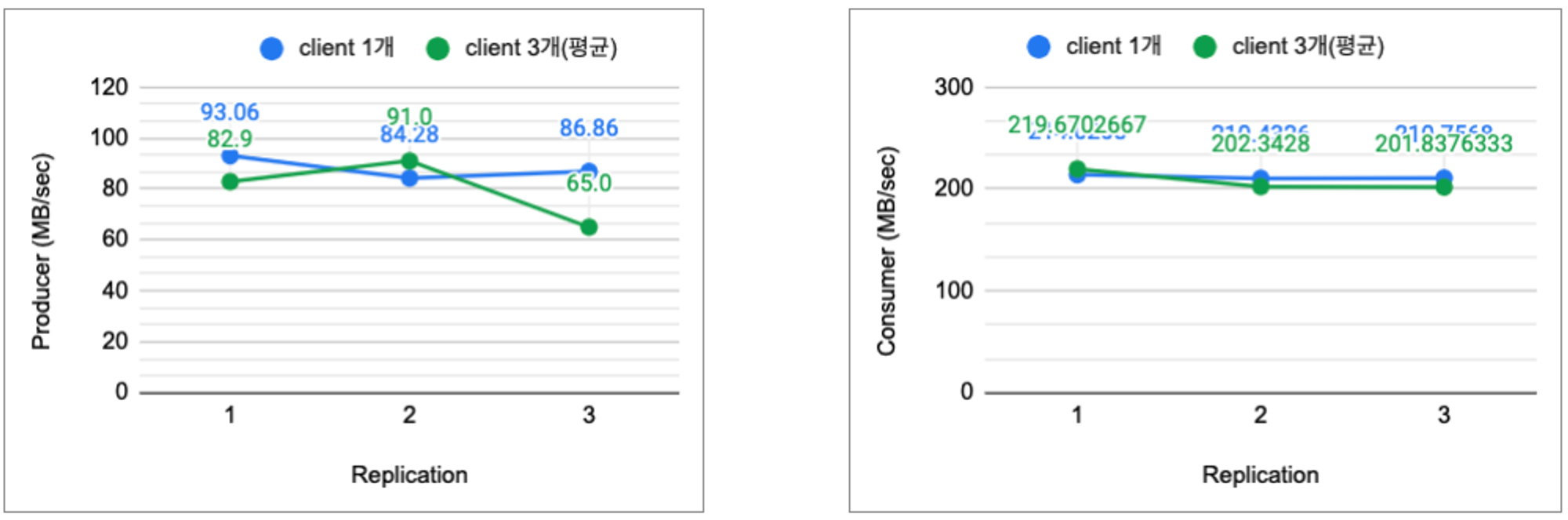
producer 3개와 consumer 3개를 동시에 측정한하여 평균 성능값을 클라이언(producer , cosumer) 1개를 실행하였을 때와 성능을 비교해보았다.
•
producer의 경우 복제본 1→2 늘어남에 따라 성능이 약 12.25% 상승했고, 복제본이 3개가 된 경우 성능 약 25.1% 하락을 보였다.
•
consumer의 경우 성능 차이가 없었다.
•
cosumer(읽기) 경우 복제본, 클라이언트 수에 관계없이 일관적인 성능을 보여준다.
•
producer(쓰기) 경우 복제본 3개를 유지하기 위해서는 클라이언트 갯수 조절이 필요하다.
결과 분석
카프카의 리소스를 증가시킨 경우 성능의 평균 약483%을 보였다. 최소한의 리소스 확보가 중요해 보인다.
현재 k8s 사용환경에서는 다른 Broker에서 튜닝가능한 항목을 튜닝 후 추가로 약 7%성능 향상을 체감할 수 있었다.
복제본을 증가 시킬수록 producer의 경우 (쓰기작업) 상대적으로 consumer(읽기작업)에 비해 일부 성능이 떨어지는 것을 확인할 수 있었다.
하지만 복제본을 여러개 두어 분산처리가 가능하게하고 안정성을 확보함했음에도 크게 성능적인 변화가 없을 확인할 수 있다.
결론 및 향후과제
리소스, Network IO Thread, 스토리지 변경 여러 항목의 설정을 변경하여 성능 실험을 수행하였다. 그 결과 현재 NE Governance, NE Flowpipe에서 배포되고 있는 카프카 상태에서 최대 약469% 이상의 성능향상이 가능했으며 Network IO Thread 등 설정을 변경하며 레플리카를 증가 시켜도 어느정도 성능 안정성을 확보할수 있었다. 카프카를 다른 어플리케이션의 영향을 최대한 받지않도록 별도의 서버 노드에서 실행시키거나 저장 스토리지를 SSD로 변경한다면 한다면 일부분 성능향상이 있을것으로 예상된다.
향후 다음 연구를 통해 다양한 환경에서 다양한 실험 방법을 통해 결과를 분석할 예정이다.
•
데이터 저장 스토리지를 SSD로 변경한 경우
•
k8s 환경에서 카프카만 별도의 node에서 실행시켰을 경우
•
SSD, HDD 저장 스토리지를 Broker 서버 각각 하나씩 분산적으로 설치한 경우
참고문헌

본 기술블로그에 게재되는 모든 컨텐츠의 저작권은 케이티넥스알(kt NexR)에서 가지고 있으며, 동의 없는 컨텐츠 수정 및 무단 복제는 금하고 있습니다. 컨텐츠(글/사진/영상 등)를 공유하실 경우 반드시 출처를 밝혀주시기 바랍니다. Copyright(c) kt NexR, Inc. All Rights Reserved. |